2023.10.11更新:根据SearchEngineLand报道,Google-Extended只是禁止Bard和其它Google的AI系统抓取,并不阻止SGE(Google的搜索生成体验)中出现网站信,因为SGE是搜索的一部分,要屏蔽搜索结果,需要禁止普通Google蜘蛛的抓取。
——-更新结束——-
人工智能依然大火。最近看到很多有意思的AI应用,我自己也在尝试在SEO工作中应用AI,以后有机会再和读者分享心得。
上篇帖子提到,AI公司抓取网站内容用于其AI训练,站长本身并不一定愿意。过去几个月,主要AI服务都在商讨怎样让网站禁止AI蜘蛛抓取。网站有权这样做是无需讨论的,但什么方法更稳妥、简单是需要考虑的。出了各种方案,我一直关注着,但直到现在才写,是因为现在才出了有效简单的方法。
为什么要禁止AI蜘蛛抓取网站内容?
因为还没有明确有效的方式得到回报。就目前情况看,AI抓取内容和搜索引擎抓取内容还有点不一样。搜索引擎抓取内容后会给网站流量,SEO们巴不得多抓点。
AI把网站内容用于训练后,网站能得到什么还不确定。ChatGPT和Bard (Google的AI聊天服务)本身基本上是不给出处的,所以网站得不到流量。
Bing和Google都在尝试把生成式AI融入搜索,也就是Bing Chat和Google的SGE(search generative experience,搜索生成体验),这两个都是会给出出处链接的。方式和排版五花八门,还在演进中,可以肯定的是,网站可以得到流量。但Bing Chat和SGE使用范围还不大,以后全面上线后:
- 用户会不会点击AI回答里的链接?会和以前的第0位结果一样带来流量吗?但第0位结果往往是不完整的,而AI已经完整回答了问题,用户还需要点击吗?
- 能给出多少链接?搜索结果页面是10个链接,生成式搜索结果会是固定数吗?会是几个?
- 什么网站能得到链接?同一个话题,用于训练的肯定不是一个网站,那哪个网站会得到链接?和做SEO一样,人人有份吗?还是将集中于权威网站?怎样提高被引用的概率?将诞生另一种优化吗?
- 点击率是多少?和目前搜索结果类似?点击率差一点,搜索流量就将差异巨大。
- 等等
还都不知道啊。
像我等小博客也就考虑一下流量回报可能性,大公司还得考虑数据安全、版权、隐私、抗攻击性等更严重的问题。
怎样禁止AI抓取网站内容?
讨论了各种方法后,巨头们显然都意识到用robots文件禁止还是最方便的方法。
8月份,OpenAI发布了他们的抓取蜘蛛的新名字- GPTBot,网站可以像禁止其他蜘蛛一样,用robots文件禁止GPTBot抓取:
User-agent: GPTBot
Disallow: /
这里有个有点吊诡、很多人又会忽略的地方:ChatGPT的训练数据来源可不一定限于GPTBot抓取的数据。OpenAI的官方文件显示,除了网上的公开信息,他们还可能使用来自第三方的授权信息,这个第三方都包括谁,就不知道了。
9月28号,Google发布了他们用于AI训练的专用蜘蛛名字: Google-Extended,同样可以用robots文件简单禁止:
User-agent: Google-Extended
Disallow: /
Google的用词是,用robots文件禁止了Google-Extended蜘蛛,就禁止了Bard和Vertex AI(Google开放给用户使用的云端机器学习平台),以及今后所有用于这些产品的模块。所以禁了Google-Extended就应该彻底不会被用于Google的AI训练了。
比较有意思的是,Google说的是:
By using Google-Extended to control access to content on a site, a website administrator can choose whether to help these AI models become more accurate and capable over time.
歌词大意:通过控制Google-Extended,网站可以选择是否要帮助AI模型成长。
禁了,就是不帮助AI成长啊,有点道德绑架的意思啊,哈哈哈。
哪些网站禁止了AI抓取网站内容?
Google的禁止方法才发布,还不知道成效。OpenAI的方法公布一个多月,已经有不少大网站禁了GPTBot。
9月22号,Originality.ai发布帖子,统计了前1000名大网站禁止GPTBot等AI蜘蛛的情况,增长速度挺快,真是残忍:
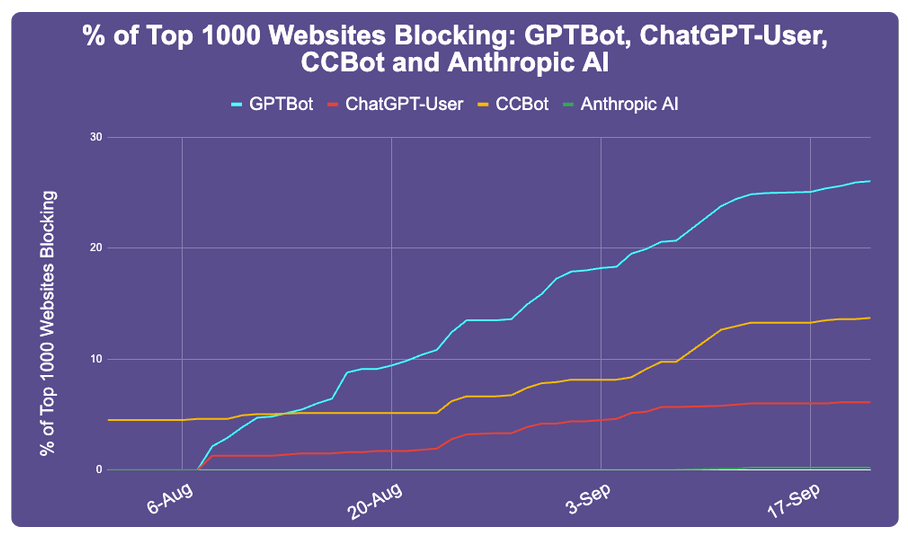
前1000名大网站,已经有242个禁了GPTBot,占了能检查到robots文件的933个网站的26%。其中包括amazon,pinterest,quora,纽约时报,CNN,华盛顿邮报,路透社,等等。
图里的CCBot是Common Crawl的蜘蛛,一个非赢利组织,是个大型网站数据库,很多AI是用CC数据库训练的,说不定就是OpenAI 的第三方数据提供商之一,所以也被不少网站给禁了。
SEO每天一贴会禁止吗?
本博客会禁止GPTBot和Google-Extended吗?至少目前不会。
虽然前一篇帖子抱怨了一下,AI抓我内容用于训练,对我有什么好处呢?不过后来再想想,随它去吧。AI是大势所趋,势不可挡,有没有我这个博客的内容,对它的影响是零。
不禁,除了有点不甘心,也没什么实质坏处。禁了AI蜘蛛,对我也没任何好处啊。还不如换个角度想,能成为这个改变世界的变革的一部分,与有荣焉。
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫 企鹅扫一扫
企鹅扫一扫


 [F16...
[F16... [F17...
[F17...
